인덱스는 조회 쿼리의 성능에 큰 영향을 미친다. 데이터의 양이 많을수록 더 극적인 효과를 볼 수 있다. 이번 포스트에서는 '개발 한 스푼' 프로젝트 중 커버링 인덱스를 적용하여 쿼리 성능을 향상시킨 경험을 공유한다.
상황
'개발 한 스푼'의 유저는 매일 본인이 선택한 CS 카테고리에 속한 질문들 중 하나를 랜덤하게 발급받는다. 해당 로직은 다음과 같은 수순으로 진행된다.
- 유저가 선택한 카테고리 가져오기
- 해당 카테고리에 속하는 모든 질문 가져오기
- 유저가 현재까지 발급받은 질문 가져오기
- 2번에서 3번을 뺀 질문들 중 랜덤하게 하나를 선택 발급
여기서 3번 유저가 발급받은 질문들은 `question_open` 이라는 테이블에 저장되어 있다. 해당 테이블에는 5만개 이상의 레코드가 저장되어있기 때문에 데이터를 효율적으로 가져올 필요가 있었다.
SQL 튜닝 : 발급받은 질문 리스트
question_open 테이블에서 어떤 유저가 발급받은 질문들을 가져와보자. PK를 제외한 다른 인덱스를 생성하지 않은 상태로 쿼리를 실행시켰다.
-- id가 1872인 유저가 발급받은 질문들 가져오기
select * from question_open qo where qo.user_id = 1872;
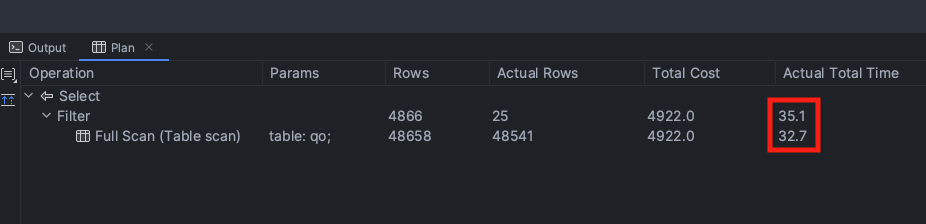
5만개의 레코드가 존재하고 인덱스를 사용하지 않을때 Table Full Scan이 일어났고 총 수행시간 35ms가 나왔고 Cost는 5000을 넘어선다. 레코드의 더 늘어날 경우를 대비해 테스트용 데이터베이스에서 130만개의 데이터를 더 넣고 테스트해보았다.
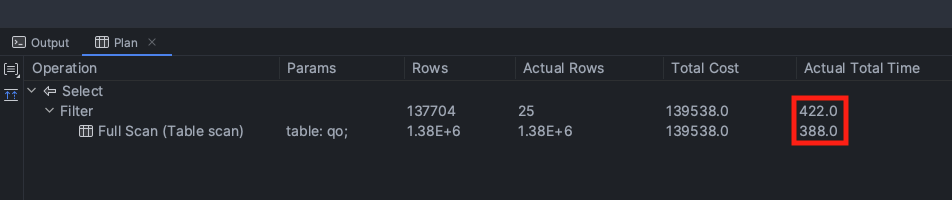
400ms가 넘는 수행 시간이 걸렸다. 쿼리 하나가 이 정도 수행시간이 걸린다면 유저 경험에 치명적일 것이다. 성능 향상을 위해 빠르게 필요한 데이터를 조회할 수 있도록 인덱스를 추가해보았다.
인덱스 추가
user_id를 동등 조건으로 조회하기 때문에 user_id로 인덱스를 생성해주었다. 단순히 인덱스를 추가한 것만으로 다음과 같이 성능이 향상되었다.

무려 2ms로 200배 가까이 성능이 향상되었다. 인덱스를 추가하면 데이터가 130만 개든 5만 개든 성능 차이가 크게 없다. 위 결과를 기준으로 이야기하자면 인덱스는 B+트리로 구성되고 리프노드는 user_id로 정렬되어 있기 때문에 O(logN)만에 user_id가 1872로 시작하는 첫 번째 레코드를 찾은 뒤 25개를 스캔한다. 총 O(logN) + 25의 시간복잡도가 나오는데 N이 130만 개든 5만 개든 logN은 충분히 작기 때문에 비슷한 결과가 나오는 것이다.
user_id는 FK(외래키)로 설정되어 있다. MySQL InnoDB에서는 FK 제약조건 설정시 해당 FK로 인덱스를 자동으로 생성하기 때문에 위 사진과 같은 성능을 낼 수 있다. 2ms면 충분히 빠르다고 생각된다.
하지만 여기서 필자는 한 단계 더 개선시킬 수 있는 가능성을 보았다.
커버링 인덱스 적용
발급받은 질문 리스트 조회 시 필요한 데이터는 질문의 id 뿐이다. 따라서 검색 결과 중 question_id만 select 시키면 된다.
-- question_id만 가져옴
select qo.question_id from question_open qo where qo.user_id = 1872;
하지만 단순히 question_id만 select한다고 성능이 향상되지는 않는다. 그 이유를 알기 위해선 잠시 InnoDB의 인덱스 탐색과정을 살펴볼 필요가 있다.
InnoDB에서 PK를 이용하지 않는 인덱스(Secondary Index)의 리프노드에는 인덱스 키와 PK 값을 가지고 있다. 레코드 데이터를 가져오기 위해서는 Secondary Index로 탐색 시 얻은 PK값을 바탕으로 PK 인덱스(Clustered Index)로 재검색한다. Clustered Index의 리프노드에는 레코드 값이 모두 들어있기 때문에 여기서 select 한 값들을 뽑아낸다.
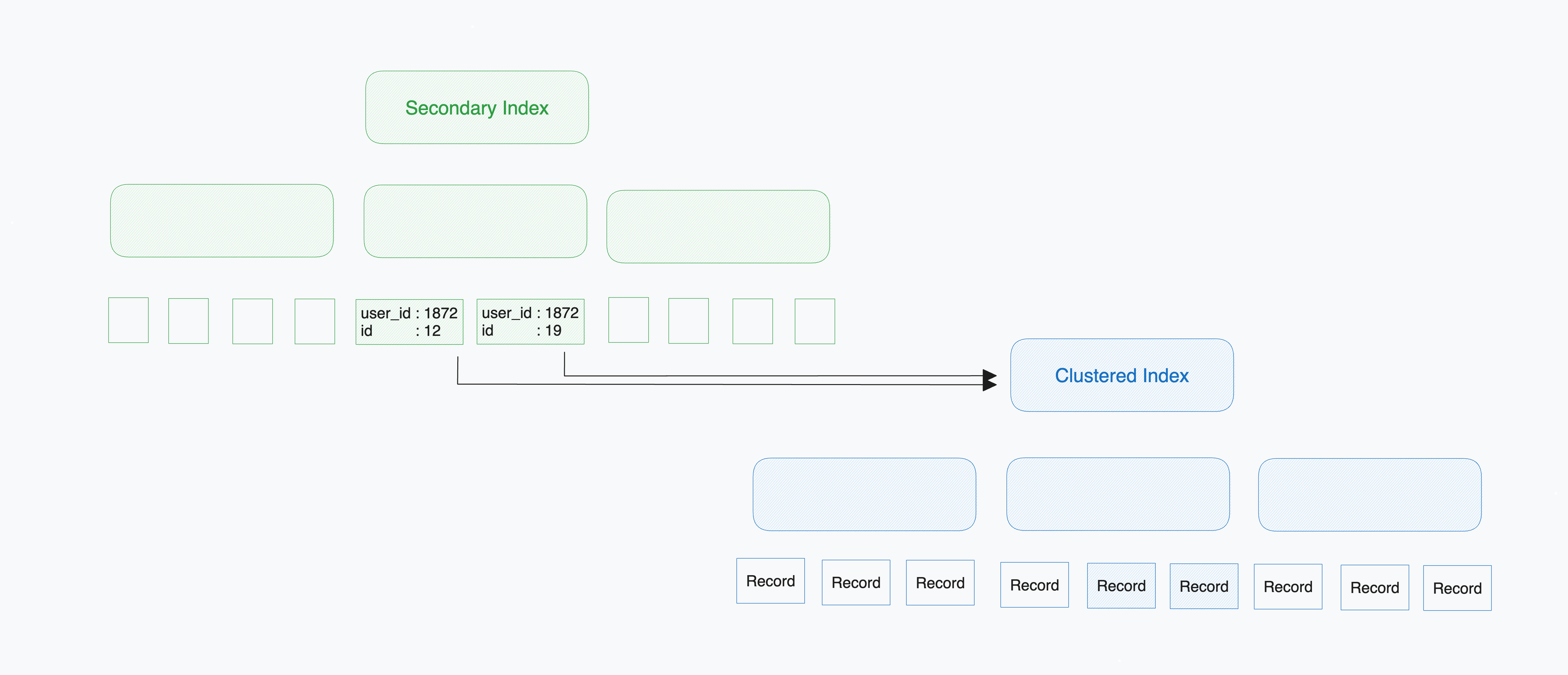
question_id만 필요할 뿐인데 레코드의 모든 정보를 얻기 위해 Clustered Index로 재탐색하는 오버헤드가 추가된다. 따라서, question_id만 select하나 모든 정보를 select하나 비슷한 수행시간이 걸리는 것이다.
이럴 때 인덱스 키에 question_id를 추가하여 커버링 인덱스를 적용시켜 재탐색을 줄일 수 있다. 커버링 인덱스란 인덱스에 포함된 정보만으로 쿼리 결과를 제공할 수 있는 인덱스를 의미한다. 필자의 쿼리의 경우 user_id와 함께 question_id를 이용해 인덱스를 만들면 인덱스 키만으로 쿼리 결과를 만들어낼 수 있다.
(user_id, question_id) 인덱스를 만들면 Secondary Index의 리프노드에 있는 정보만으로 결과를 만들어낼 수 있어 Clustered Index로 재탐색하여 레코드의 모든 데이터를 읽는 과정이 생략된다. 따라서, (user_id, question_id)로 인덱스를 만들고 적용했다.

실행계획에서 Covering Index가 사용되었음을 알려준다. 실행시간은 0.03ms로 user_id만 인덱스로 사용했을 때와 비교해 90% 이상 개선되었다.
마치며
커버링 인덱스를 적용하지 않고 user_id 인덱스만 적용해도 2ms로 충분히 빠른 수행시간을 가진다. 다만 커버링 인덱스를 사용해 효과를 직접 체감할 수 있었다는 것에 의의가 있다.
조회 성능을 높이기 위해 인덱스를 생성하지만 인덱스를 무분별하게 많이 생성하는 것 또한 좋지 못하다. 인덱스는 추가적인 메모리를 사용하는 것이고, 너무 많은 인덱스가 존재할 경우 옵티마이저가 잘못된 인덱스를 선택할 경우도 존재한다. 언제나 그렇듯 상황에 맞춰 적절하게 인덱스를 생성하여 사용하도록 하자.
GitHub - kids-ground/adevspoon-backend: CS 질문 - adevspoon-backend
CS 질문 - adevspoon-backend. Contribute to kids-ground/adevspoon-backend development by creating an account on GitHub.
github.com
'Server & DevOps' 카테고리의 다른 글
| OS, 어플리케이션에서의 데드락 (4) | 2024.07.12 |
|---|---|
| 경쟁상태와 동기화 매커니즘의 활용 (3) | 2024.07.04 |
| Github Actions를 활용한 브랜치 전략 맞춤 자동화 (2) | 2024.06.08 |
| ALB와 CodeDeploy 를 이용해 무중단 배포 파이프라인 구축하기(ft. Terraform) (2) | 2024.06.07 |