경쟁상태와 동기화 매커니즘 에서 경쟁상태를 해결하기 위한 Block & WakeUp 잠금 방식에 대해 알아보았다. 해당 방식은 대기하는 스레드가 Lock을 획득하기 전까지 블로킹된다. 만약 어떤 문제 때문에 원하는 Lock을 획득하지 못하고 무한히 대기하게 된다면 어떻게 될까? 어느 상황에서 이러한 문제가 발생할 수 있으며 어떻게 해결할 수 있는지 살펴보자.
OS에서의 데드락 개념
데드락이란 두 개 이상의 프로세스(스레드)가 서로가 가진 자원을 기다리며 무한히 대기하는 상황을 일컫는다. 아래 그림과 같은 상황이다.(여기서 자원이란 파일, 프린터, CPU, Lock 등 프로세스가 사용가능한 모든 것)
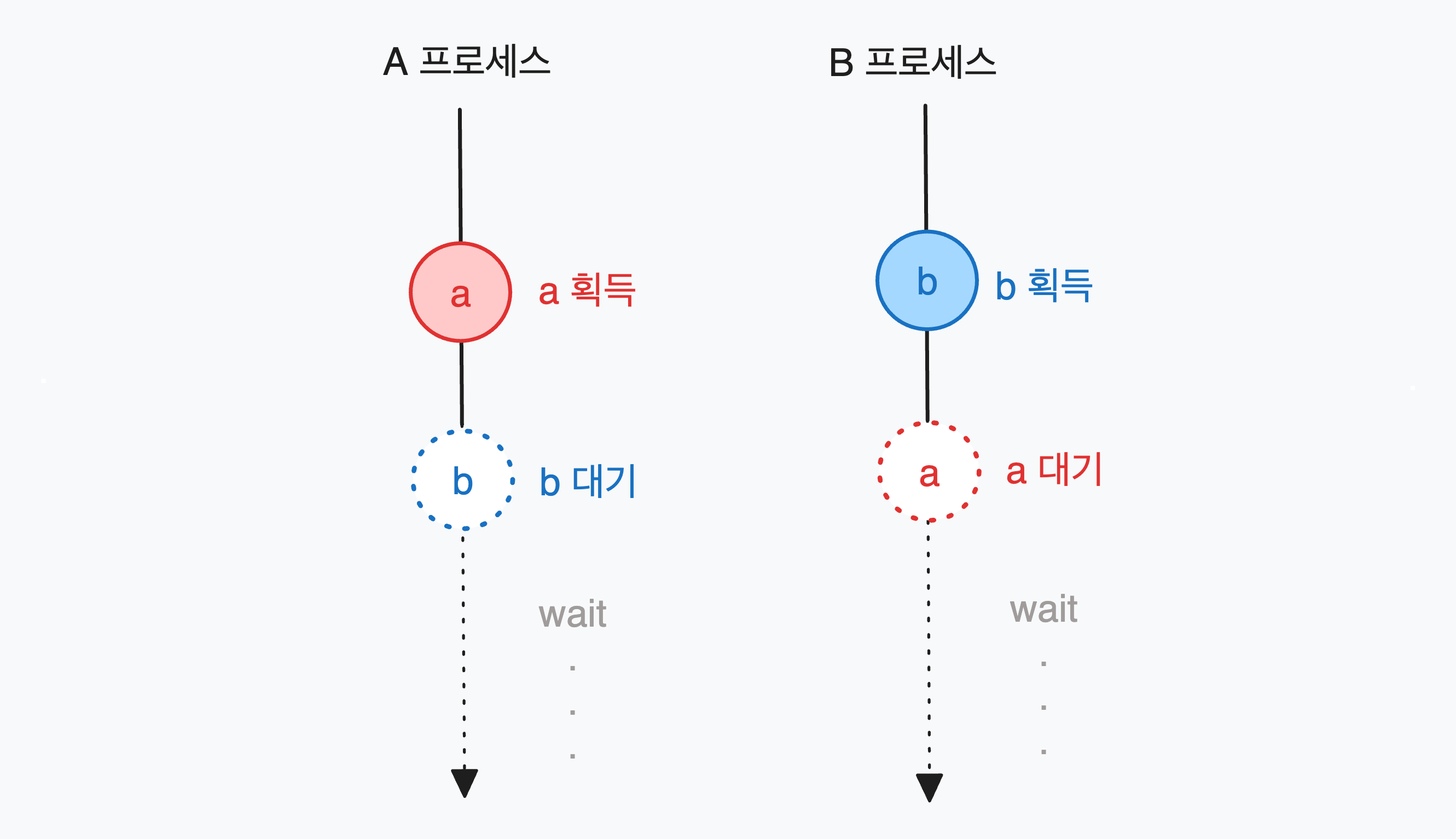
A 프로세스와 B 프로세스 각각 a,b 자원을 소유 후 상대가 가지고 있는 자원을 요청한다. 두 자원은 각 프로세스가 소유중이므로 자신이 가진 자원을 소유한 채로 대기 상태(Block)가 된다. 어느 쪽에서도 자원을 반납하지 못하기 때문에 두 프로세스는 무한히 대기하게 된다. 이러한 상황이 데드락이다.
OS 레벨뿐만 아니라 Lock 매커니즘을 활용하는 데이터베이스, 어플리케이션 수준에서도 데드락이 발생할 수 있다. 어느 수준에서든 맡은 작업을 무사히 수행해야할 스레드가 무한히 멈춰있다는 것은 매우 치명적인 문제다.
데드락의 발생조건
데드락은 아래 4가지 조건이 모두 충족될 때 발생한다.
- 상호배제(Mutual Exclusion) : 하나의 자원은 하나의 프로세스만 사용할 수 있다.
- 점유 대기(Hold and Wait) : 프로세스가 자원을 가진 채 다른 자원을 획득하기 위해 대기
- 비선점(No preemption) : 다른 프로세스가 가진 자원을 강제로 뺏지 못한다.
- 순환 대기(Circular wait) : 프로세스들이 서로가 가진 자원을 가져가기 위해 순환 형태로 대기중이다.
위 조건을 모두 충족하여 데드락이 발생하는 상황의 예시로 '식사하는 철학자 문제'가 있다. 해당 문제에 대한 설명은 다음과 같다.
다섯 명의 철학자가 원형 테이블에 앉아 있고 테이블 위에는 다섯개의 포크만 존재한다. 철학자들은 사색과 식사를 번갈아 하며, 식사는 자신의 왼쪽과 오른쪽 포크를 모두 든 상태에서만 가능하다. 포크를 들 때는 자신 주위의 포크만 들 수 있으며, 두 포크를 동시에 들 수 없다.(하나씩 들어야 한다는 의미)
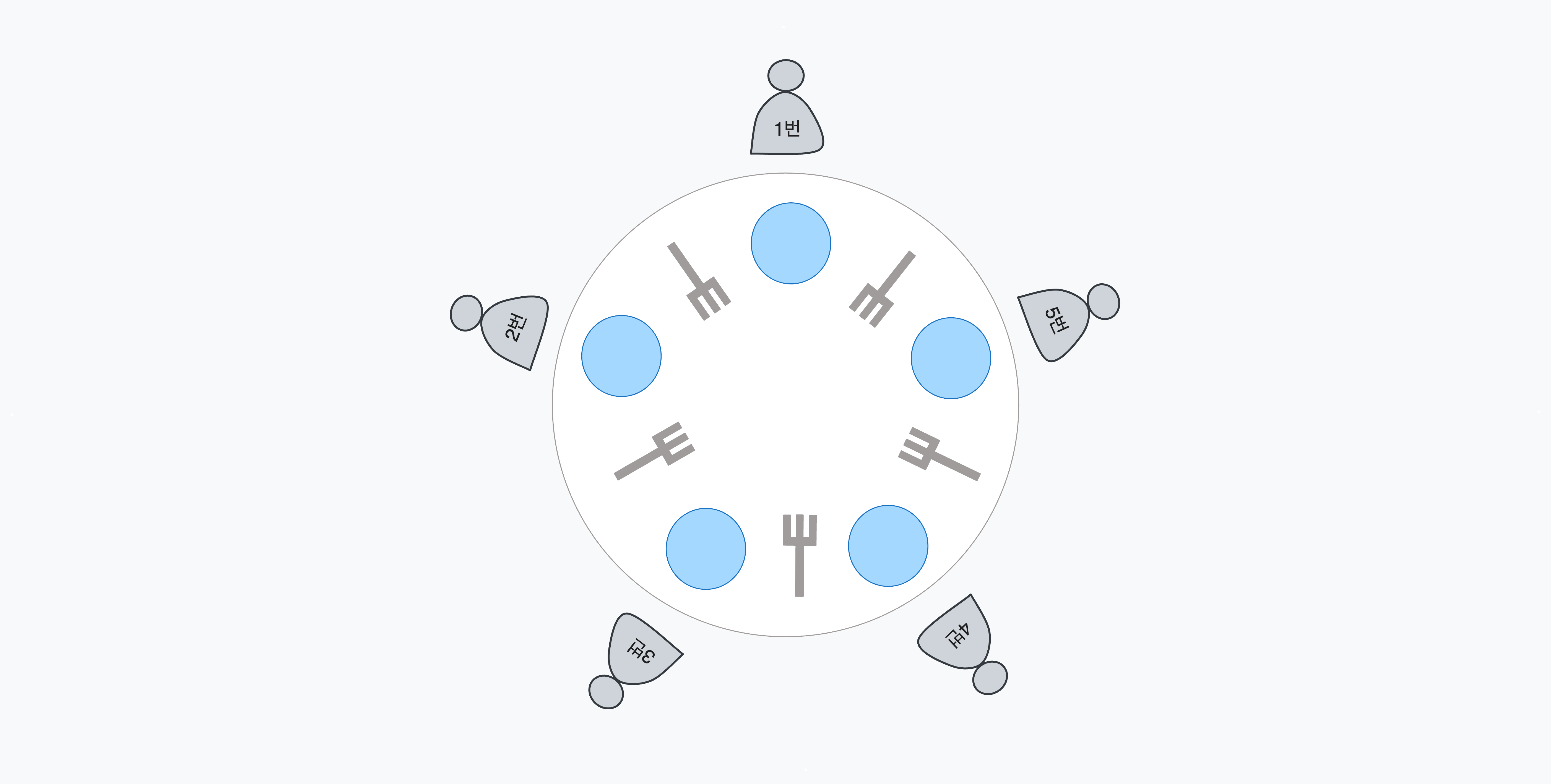
이 상황에서 모든 철학자가 식사를 시도할 때 데드락이 발생할 수 있다. 모든 철학자가 식사를 위해 자신의 왼쪽 포크를 먼저 집은 후 오른쪽 포크를 집는 상황을 가정해보자.
- 모든 철학자가 각자 자신의 왼쪽 포크를 집는다.
- 1번 철학자가 오른쪽 포크를 집으려고 시도한다.
- 해당 포크는 2번 철학자 입장에서 왼쪽 포크이므로 이미 가져간 상태이다.
- 1번 철학자는 2번 철학자가 포크를 내려놓을 때까지 대기한다.
- 2,3,4번 철학자 또한 동일한 상황으로 대기한다.
- 5번 철학자 또한 마찬가지로 우측인 1번 철학자가 포크를 내려놓을 때까지 대기한다.
위 상황은 데드락 조건을 모두 충족한다. 각 포크는 한 명의 철학자만 사용할 수 있으므로 상호배제를 상태이며, 다른 철학자가 가진 포크를 뺏을 수 없으므로 비선점이다. 또한, 자신의 오른쪽 포크를 든 상태로 자신의 왼쪽 포크를 대기하며, 대기하는 형태가 원형구조로 점유 대기, 순환 대기 상태임을 알 수 있다.
이처럼 철학자(프로세스) 모두가 원형태로 자신의 우측 철학자가 가진 포크(자원)를 기다리다 무한 대기에 빠지는 모습이 데드락 상황과 같다. 철학자들이 식사를 못하는 상황처럼 치명적인 데드락 상황. 어떻게 제어할 수 없을까?
데드락을 제어하는 방식은 크게 세 분류로 나눠서 볼 수 있다. 하나씩 살펴보도록 하자.
- 데드락 발생을 미리 방지하는 방법(예방, 회피)
- 데드락 발생 이후 복구시키는 방법(탐지 후 회복)
- 데드락 발생하더라도 무시하는 방법
데드락 예방(Prevention)
예방은 데드락이 발생하는 상황 자체가 생기지 않도록 하는 방법이다. 프로세스에게 자원을 할당하더라도 반드시 데드락이 발생하지 않는다는 것을 보장한다. 예방은 데드락이 발생하는 4가지 조건 중 하나를 부정하는 방식으로 '4가지 조건을 모두 만족하는 경우에만 데드락이 발생한다'라는 맹점을 노린 방법이다.
상호배제를 부정한다면 하나의 자원을 여러 프로세스가 공유해서 사용할 수 있다. Lock과 같이 임계영역에서의 동시성 문제 해결하는 방식에는 이를 적용하지 못한다. 읽기 전용 파일 접근과 같이 상호배제가 필수적이지 않는 자원에만 적용이 가능하다.
점유대기를 부정한다면 실행에 필요한 자원을 한 번에 모두 획득 후 실행시킨다는 의미이다. 이런 경우 당장에 필요하지 않은 자원까지 미리 획득함으로 시스템 전체적인 성능이 떨어질 수 있다. 만약 자원을 모두 획득하지 못하면 획득한 자원을 모두 반납 후 대기한다. 이 경우 불필요한 획득/반납 과정이 생긴다고 볼 수 있다. 또한, 대기 중인 프로세스 중 우선순위가 낮은 프로세스가 자원을 할당받지 못하는 시간이 길어져 Starvation(기아) 현상이 발생할 수도 있다.
비선점을 부정한다면 다른 프로세스의 자원을 강제로 뺏는 것을 허용한다는 의미다. 다른 프로세스의 요청에 프로세스가 가진 자원을 내놓아야 하는데 이때 자원을 내놓는 프로세스가 수행중이었던 과정을 저장 또는 롤백시키는 과정이 필요할 것이다. 따라서, CPU나 메모리처럼 저장, 롤백이 용이한 자원에만 적용하다.
순환대기를 부정할려면 자원 획득의 과정이 오름차순이어야 한다. 무슨 의미냐면 각 자원에 가중치를 할당하고 프로세스가 자원 요청시에는 먼저 획득한 자원보다 가중치가 큰 자원에만 획득 요청을 보내는 것이다. 만약 현재 획득한 자원의 가중치가 가장 크다면 다른 자원을 획득할 수 없고 가진 자원을 반납시켜야한다. 프로세스의 자원 획득 순서에 대한 배치 설계, 자원의 가중치 설정 등이 매우 중요한 요소가 된다.
상호배제는 동시성 문제가 발생하지 않는 자원에만 적용할 수 있다는 제한이 존재하고 상호배제를 제외한 방식들은 데드락 상황을 막기위한 안전장치를 만듦으로써 전체적으로 처리율(성능)이 저하되는 문제가 보인다.
데드락 회피(Avoidance)
회피 또한 데드락 상황을 방지하는 기법 중 하나이다. 예방은 데드락 없는 상황으로 미리 구성한 것이라면 회피는 시뮬레이션을 통해 자원 할당 상황마다 실시간으로 확인한다.
구체적으로 실제 자원을 할당하기 전 자원 할당을 미리 검사(시뮬레이션)하여 데드락이 발생할 수 있는 가능성이 존재한다면 자원을 할당시키지 않는 방식이다. 시뮬레이션 결과 데드락에 안전한 상태를 Safe State, 데드락 가능성이 존재하는 상태라면 Unsafe State라고 보고 Safe State일 때만 자원을 할당한다. Unsafe State는 반드시 데드락이 발생하는 것이 아닌 가능성이 있는 상황을 의미하는데 이 상태를 배제함으로써 데드락을 회피하는 것이다.
대표적으로 Resource Allocation Graph(RAG, 자원 할당 그래프)를 활용하는 방식과 Banker's Algorithm(은행원 알고리즘)이 존재한다.
자원 할당 그래프(RAG) 활용
자원 할당 그래프는 프로세스가 자원을 할당받은 상태, 자원을 요청한 상태를 그래프로 표현하여 사이클이 발생하는 경우에 데드락의 가능성을 확인한다.
RAG는 자원 타입(프린터, CPU 코어) 당 하나의 인스턴스를 가지는 경우를 표현할 때 싱글 인스턴스 RAG로, 둘 이상의 인스턴스를 가지는 경우 멀티 인스턴스 RAG로 표현할 수 있다. 하나의 인스턴스를 가지는 상황에서 그래프로 단순하고 명확하게 표현할 수 있어 싱글 인스턴스 RAG로 데드락 가능성을 체크한다. 하지만 멀티 인스턴스의 상황은 그래프 구조가 복잡해져 RAG 대신 은행원 알고리즘을 사용하는게 효율적이다. 멀티 인스턴스 RAG를 활용한 방법이 궁금하다면 이 블로그에서 참고 가능하다.
싱글 인스턴스 RAG(이하 RAG)는 다음과 같은 Vertex와 Edge로 이루어져 있다.
- Vertex
- 자원(Resource, 이하 R) 정점, 프로세스(Process, 이하 P) 정점
- Edge
- claim - P가 미래에 R을 요청할 수 있음(P -> R 점선)
- request - P가 R을 요청한 상태(P -> R 실선)
- allocation - P에 R이 할당된 상태(R -> P 실선)
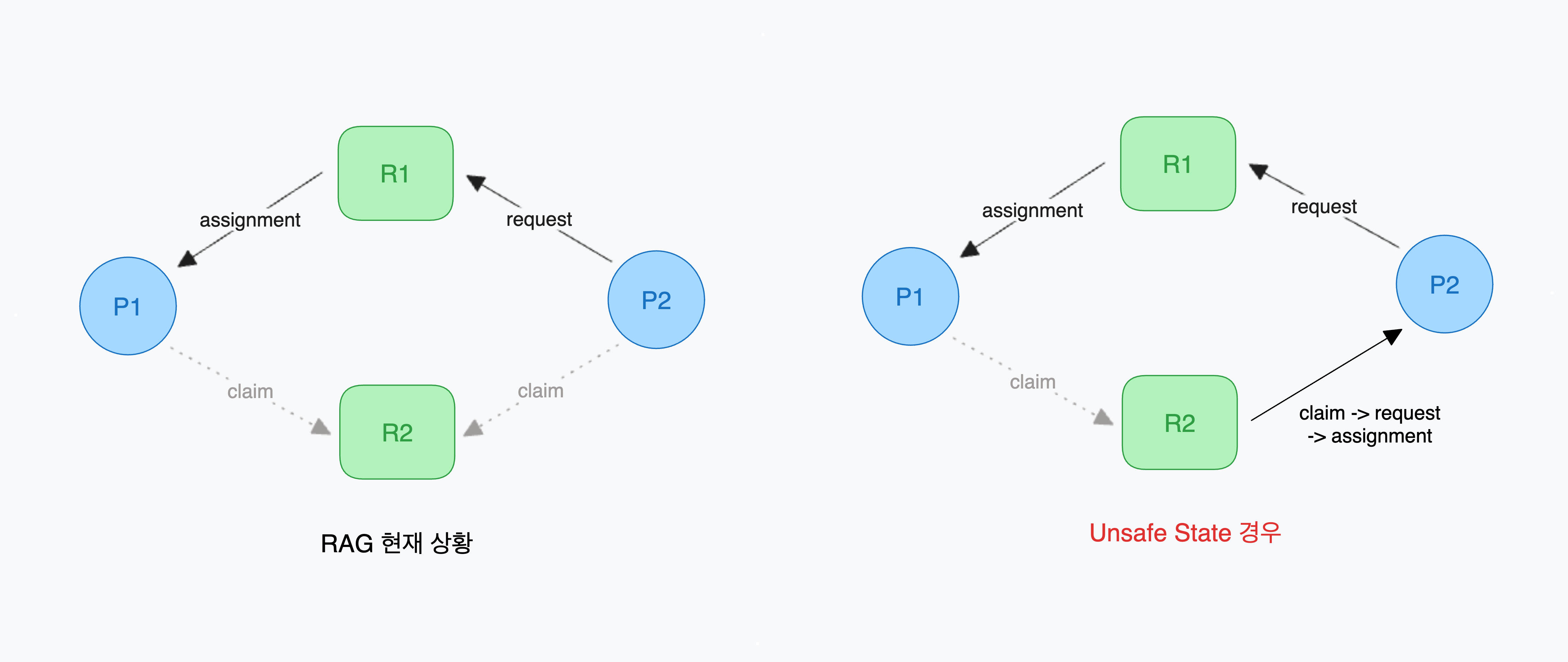
위 그림의 좌측 그래프는 P1이 R1을 할당받은 상태이며 P2가 R1을 요청한 상태이다. 미래에 P1, P2가 R2를 요청할 수 있음도 표현하였지만 그래프에 사이클이 확인되지는 않는다.
이후 P2에서 R2를 요청하는 시점이 되었을때 P2를 할당받은 프로세스가 아직 없기 때문에 우측 그림처럼 할당받았을 때의 상황을 시뮬레이션한다. P2 -> R2 Claim Edge가 R2 -> P2의 Allocation Edge로 변경 시 사이클이 발생하는 것을 볼 수 있다. 자원이 해제되지 않은 상황에서 P1이 R2를 요청한다면 데드락이 걸릴 수 있다. 물론 P1 -> P2로 Request 되기 전 R1이나 R2 자원 해제가 일어날 수 있지만 데드락 가능성이 존재하는 Unsafe State이기 때문에 실제로 자원을 할당하지 않는다.
RAG를 이용한 회피의 핵심은 모든 간선을 통해 그래프에 사이클(순환대기) 발생을 확인하는 것이다. 사이클이 생긴다면 Unsafe State(데드락 가능성 존재)로 확인하고 자원을 할당하지 않는다.
은행원 알고리즘
멀티 인스턴스 상황에서 데드락 회피를 위한 알고리즘이다. 대출 시 돈(자원)을 갚을 능력이 있는지 확인하는 과정과 유사해 이같은 이름이 붙여졌다. 은행원 알고리즘은 Max, Allocation, Need, Available 테이블을 이용한다.
- Max[i][j] : i 프로세스가 진행하는데 j 자원이 총 몇 개 필요한지를 나타낸다.
- Allocation[i][j] : i 프로세스가 현재 j 자원을 몇 개 가지고 있는지 나타낸다.
- Need[i][j] : i 프로세스가 추가로 필요한 j 자원의 수를 나타낸다.(Max[i][j] - Allocation[i][j])
- Available[j] : 할당 가능한 j 자원의 수를 나타낸다.
은행원 알고리즘의 핵심은 요청 자원 할당 후 프로세스들이 데드락 없이 실행할 수 있는 안전 순서(Safe Sequence)를 찾는 것이다. 안전 순서가 존재할 경우 Safe State임을 보장한다. Safe Sequence를 찾는 방식은 다음과 같다.
- 시뮬레이션을 준비한다.
- 우선 프로세스가 요청한 자원 수을 확인한다.( <= Available[j]) 만족하지 않는다면 곧바로 실패한다.
- 프로세스가 요청한 자원 수를 Allocation[j]에 더하고, Need[i][j], Available[j]에서 뺀다.
- Available 배열 정보를 Work 라는 이름의 배열로 복사한다.
- 프로세스의 종료 여부를 확인하는 Finish[i] 배열을 False 초기화한다.
- 현재 프로세스들을 순회하며 Work 배열로 Need[i]를 만족하는지 확인한다.(Need[i] <= Work)
- 확인된 프로세스에게 자원을 할당하면 프로세스는 무사히 작업을 마칠 수 있다.
- 따라서, 해당 프로세스가 가진 자원 Allocation[i]를 Work 배열로 반납시킨다.
- Finish[i] = true로 작업이 무사히 완료될 수 있음을 표시한다.
- (2,3) 을 Finish가 전부 True가 될때까지 반복한다.
- 모두 True가 되는 상황(안전순서)을 찾는다면 자원 할당을 허락한다.
- 안전순서가 없다면 Unsafe State로 요청된 자원 할당을 보류한다.
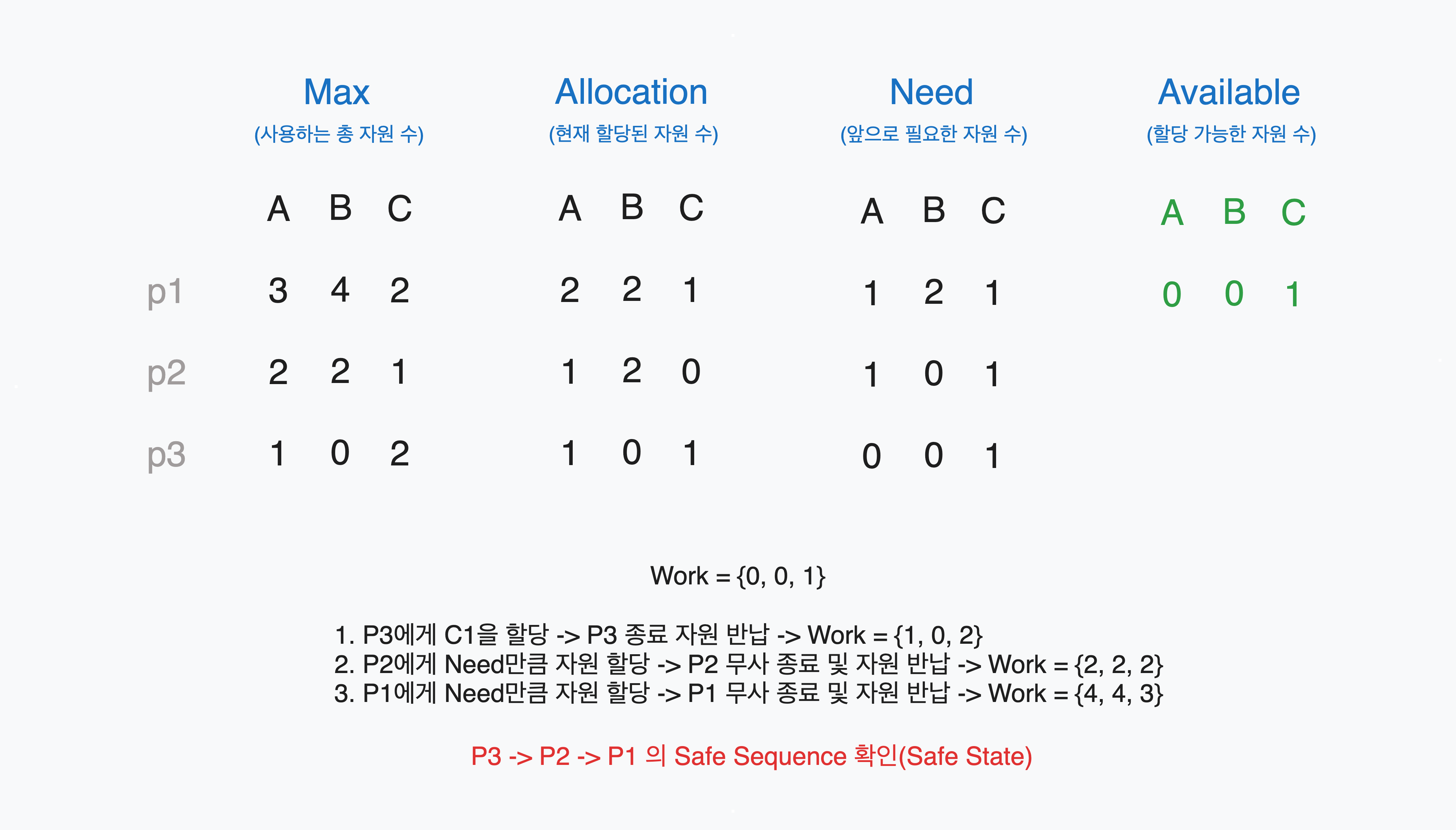
은행원 알고리즘은 자원 요청을 받아 시뮬레이션한다하여 Resource-Request Algorithm 이라고 부르기도 하며, Safe Sequence를 찾아가는 과정만을 Safety Algorithm이라고 따로 떼어서 부르기도 한다. 이런 은행원 알고리즘은 안전 순서를 찾기 전까지 모든 처리 순서를 탐색한다. 때문에 프로세스의 수가 많아질수록 시스템 부하가 증가한다는 단점이 있다.
RAG나 은행원 알고리즘은 모두 미래에 어떤 자원을 사용할지를 알고 있어야 사용할 수 있다.(RAG의 claim edge, 은행원의 Max Table) 또한, 회피를 위해 자원 할당 시마다 위 알고리즘들로 체크하기 때문에 시스템에 큰 부하가 생긴다. 때문에 부하가 심한 데드락 회피 방식보다는 탐지 후 회복하는 데드락 복구 방식을 많이 사용한다.
데드락 탐지 및 회복
앞선 회피와 예방은 데드락 상황이 발생하지 않도록 하는 안정장치이다. 하지만 이를 위해 시스템의 부하, 성능의 희생이 불가피했다. 데드락 복구 방식은 데드락 발생을 허용하는 대신 실행 중 데드락을 탐지하고 발견 시 회복하는 방식이다. 따라서, 복구는 데드락을 탐지하는 단계와 탐지 시 회복하는 단계로 나누어진다.
데드락을 탐지하는 방법(DeadLock Detection Algorithm)은 위에서 설명한 회피 방식들을 응용한다. 회피는 데드락이 가능한 상황을 시뮬레이션, 탐지는 현재 상황이 데드락인지 체크하는 것에서 차이가 날 뿐이다. RAG을 응용한 Wait-for graph와 은행원 알고리즘을 응용한 방법 두 가지를 알아보자.
Wait-for Graph
Wait-for Graph는 RAG를 응용한 방식이다. RAG는 자원과 프로세스 정점간 관계를 간선으로 표현하였다면 Wait-for Graph는 프로세스 정점만을 이용해 간결하게 표현한다. 간선의 방향은 프로세스1(P1)이 프로세스2(P2)가 가진 자원을 기다리고 있다면 P1 -> P2 로 표현한다.
현재 데드락 상황인지(다른 프로세스가 가진 자원을 순환형태로 대기중인지)를 판단하면 되기 때문에 프로세스간 대기 관계만으로 파악할 수 있다. 사이클이 발생 시 데드락으로 판단하며, RAG와 마찬가지로 싱글 인스턴스인 상황에서 사용하기 효과적이다.
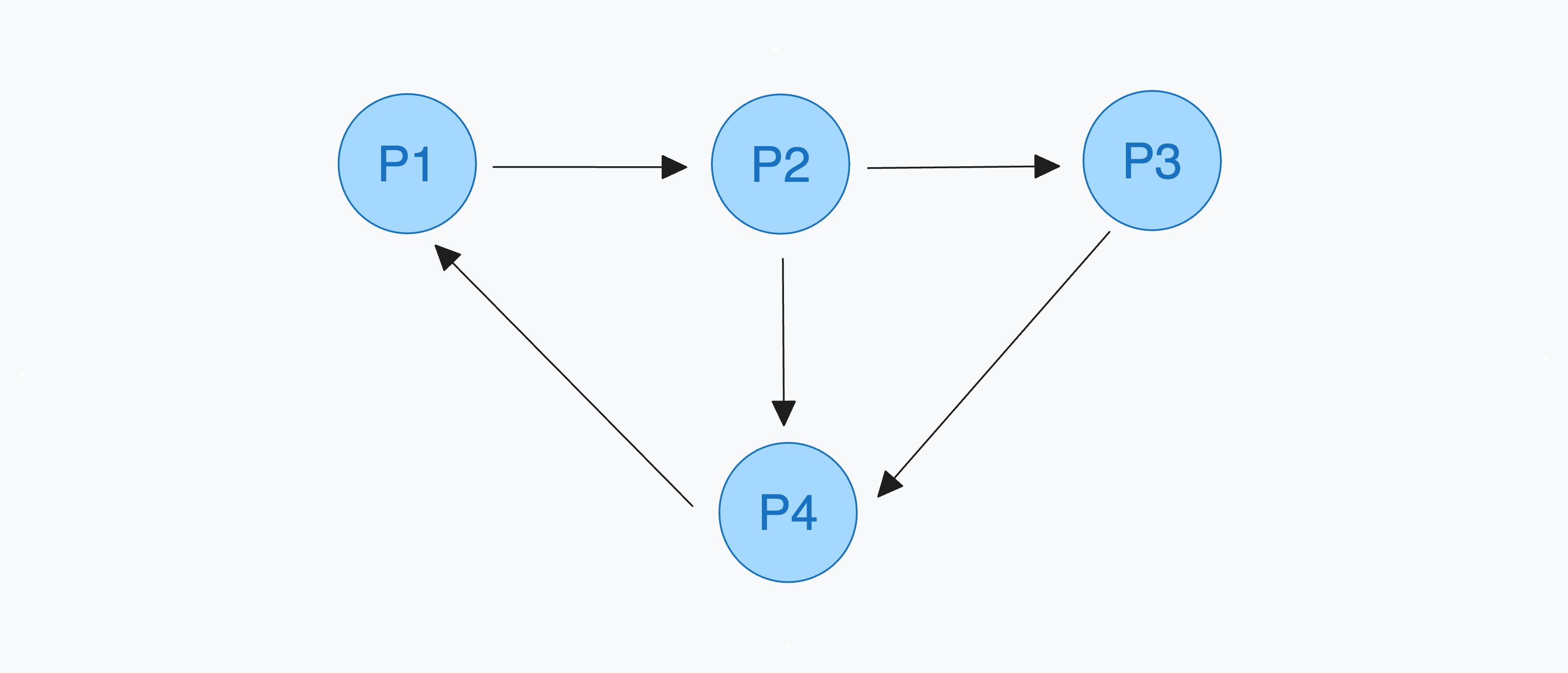
은행원 알고리즘 응용
멀티 인스턴스 상황에서 데드락 탐지는 은행원 알고리즘을 응용할 수 있다. 기존 은행원 알고리즘은 예측을 위해 Max, Need 와 같이 미래에 사용될 자원들을 미리 알고 있어야 했다. 탐지는 현재 상태만으로 데드락 상황인지 판단하므로 Max, Need 테이블 대신 현재 요청 대기중인 자원을 표현하는 Request 테이블을 이용한다.
- Allocation[i][j] : i 프로세스가 현재 가지고 있는 j 자원의 수
- Request[i][j] : i 프로세스가 현재 요청 대기중인 j 자원의 수
- Available[j] : 할당 가능한 j 자원의 수
데드락을 판단하는 기준 또한 은행원 알고리즘과 흡사하다. 현재 할당 가능한 자원과 할당 해제 될 자원을 이용해 Safe Sequence를 만들 수 있으면 된다.
- 탐지 준비
- Available 배열을 Work에 복사
- Finish[i] 배열을 False로 초기화(프로세스 실행완료 체크용)
- Allocation[i]가 전부 0인 프로세스는 미리 Finish[i] = true (점유대기 위배이므로)
- 프로세스들을 돌며, Request[i]의 자원들을 할당할 수 있는지 확인(Request[i] <= Work)
- 2번 확인된 프로세스는 완료 체크 및 자원 회수
- Finish[i] = true 체크
- 해당 프로세스가 완료 후 회수될 자원 Work 배열에 추가
- (2-3) 과정을 반복하며 모든 프로세스가 완료될 수 있는지 확인
- Finish[i] 가 모두 True가 되는 상황이 있다면 데드락 없이 실행된다는 의미
- 없다면 데드락 상황
탐지 알고리즘의 수행빈도
탐지 알고리즘의 수행빈도는 명확한 답이 있기보다는 각 시스템의 상황에 맞춰 수행빈도를 정하는 것이 좋다. 데드락이 자주 발생하는 시스템인지, 데드락 발생시 영향을 받는 프로세스의 수가 많은지 등을 고려하여 얼마나 빈번하게 실행시킬지를 결정하는 것이 좋다. 너무 빈번한 실행은 회피 알고리즘과 마찬가지로 오버헤드의 문제가 존재하고 반대로 너무 뜸한 실행은 데드락 상황을 빠르게 판단하지 못해 시스템이 진행이 중단될 수도 있어 치명적이다.
탐지 수행 타이밍 또한 중요한 요소이다. 요청 즉시 자원을 획득하지 못할때, 혹은 특정 주기에 맞춰 실행할 수도 있는데 각각이 다음의 특징을 가진다.
- 요청 즉시 자원을 획득하지 못할때 수행
- 데드락을 유발한 자원요청을 특정할 수 있다. 하지만 회피 알고리즘만큼은 아니지만 오버헤드가 크다는 단점이 있다.
- 특정 주기마다 수행
- 오버헤드를 줄이는 대신 데드락을 유발한 자원요청이 어떤 것인지 특정하기 어렵다. 또한 데드락 상황이 전자에 비해 긴시간 유지될 수 있다는 특징이 있다.
데드락 회복하기
데드락을 탐지한 이후에 상황을 해결해야 시스템이 정상적으로 동작을 진행할 수 있다. 이를 위한 회복방법은 크게 2가지 존재한다.
- 데드락 걸린 프로세스 종료
- 데드락에 연루된 모든 프로세스를 종료할지, 프로세스를 하나씩 종료시킬지로 나누어진다. 후자의 경우 우선순위, 현재까지 수행된 시간 등 여러 조건을 확인한 후에 종료시킬 프로세스를 결정해야 한다.
- 자원을 선점하기
- 다른 프로세스가 가진 자원을 뺏는 방법이다. 물론 다짜고짜 뺏는 것이 아닌 어떤 프로세스, 어떤 자원을 선점을 할 것인가에 대한 선택이 필요하다. 이때 자원을 뺏긴 프로세스를 롤백시키기, 우선순위에 따라 자원을 뺏을 경우 매번 같은 프로세스의 자원을 뺏어 생기는 기아현상 발생에 조심해야한다.
데드락 무시
데드락이 발생하지 않는다는 가정하에 아무런 조치도 취하지 않는 방법이다. 지금까지 살펴본 것처럼 데드락 처리를 위해 추가적인 오버헤드들이 발생한다. 데드락 상황은 거의 발생하지 않으므로 오버헤드를 없애고 무시하는 방식을 선택할 수 있다. 현대의 OS에서는 데드락을 무시하는 경우가 많다. 대신 타임아웃과 같은 방식으로 설정된 시간이 지난 후에도 응답이 없을 경우 사용자에게 프로세스 처리를 맡긴다.
물론 어플리케이션 수준에서 데드락을 무시할 수는 없다. 비즈니스에 치명적일수도 있어 데드락 상황을 최소하하고 상황이 발생하더라도 발빠르게 대처할 필요가 있다.
어플리케이션에서의 데드락
어플리케이션(응용 프로그램)을 개발할때 발생할 수 있는 데드락을 처리하는 것은 프로그래머의 책임이다. 데드락은 다수의 스레드가 노드 내 자원을 대기할 때나 데이터베이스에 다수의 트랜잭션이 처리될 때 발생할 수 있다. 트랜잭션을 사용하면 데이터 처리 순서화를 위해 Lock을 사용하게 되고 데드락 상황이 발생할 수 있다.
어플리케이션 수준에서 발생하는 데드락은 무시할 수 없는 경우가 대부분이다. 그렇다면 프로그래머는 데드락 상황을 어떻게 해소할 수 있을까?
현실적인 데드락 최소화
가장 먼저, 데드락이 발생할 수 있는 가능성을 최소화 시키는게 좋을 것이다. 그럼에도 복잡한 비즈니스에서는 데드락이 발생할 수 있으므로 이에 데드락 상황에 대한 대비가 필요하다.
접근 순서화로 가능성 최소화
트랜잭션간 혹은 트랜잭션 내 자원에 접근하는 로직들을 순서화시키는 방식이다. 자원 접근 로직이나 트랜잭션에 가중치를 부여해 가중치가 낮을 순으로 먼저 실행하는 방식으로 순서화시킬 수 있다.(순환대기 위배시키기) 하지만 지속적으로 유지보수하고 새 기능 로직이 추가되는 시스템에서 확실한 순서화를 기대하기는 어렵다.
Lock 사용 범위 최소화
Lock을 사용하는 범위를 최소화하는 것도 하나의 방법이다. 획득 후 로직을 실행 후 최대한 빠르게 반납함으로써 데드락 가능성을 낮출 수 있다.
Lock을 전부 획득하고 실행하기
데드락 예방법에서 점유대기를 위배하는 방법과 같이 로직 실행 시 사용하는 모든 Lock을 획득 후 진행하는 방법이다. 만약 하나라도 Lock을 획득하지 못하면 가진 자원을 모두 반납하고 대기 or 실패시킨다. 빈번한 Lock 획득/반납 및 아직 필요하지 않는 Lock 획득으로 인해 시스템 성능이 크게 떨어질 수 있다.
트랜잭션, Lock 대기/반납 타임아웃 설정
가장 현실적인 방법이라고 생각한다. 트랜잭션 실행 시 타임아웃을 설정하여 일정 시간안에 끝나지 않으면 실패로 처리하거나 Lock을 대기하는 시간 설정, Lock 소유기간을 설정해 자원을 강제로 회수(비선점 위배시키기)할 수 있도록 만드는 것이다. 이 경우 타임아웃 시간을 어느정도로 설정하는지가 시스템의 성능에 영향을 미친다.
모니터링으로 Lock 강제종료
Lock을 모니터링하는 것도 하나의 방법이다. 모니터링을 통해 데드락 상황이 발견되면 프로세스를 직접 강제 종료시킬 수도 있다. 데드락을 탐지를 수행할 수도 있으며, 단순히 해당 Lock의 소유시간만 확인할 수도 있다.(물론 이 과정은 자동화시키는게 좋을 듯하다)
데드락 주기적으로 탐지하기
OS의 데드락 탐지와 마찬가지로 어플리케이션에서도 데드락을 탐지할 수 있다. 예를 들어, MySQL InnoDB의 경우 내부적으로 데드락을 탐지하고 있다.(아마 Wait-for Graph를 사용하는 것으로 알고 있다.)
'Server & DevOps' 카테고리의 다른 글
| 경쟁상태와 동기화 매커니즘의 활용 (3) | 2024.07.04 |
|---|---|
| Covering Index로 쿼리 성능 개선하기 (0) | 2024.06.14 |
| Github Actions를 활용한 브랜치 전략 맞춤 자동화 (2) | 2024.06.08 |
| ALB와 CodeDeploy 를 이용해 무중단 배포 파이프라인 구축하기(ft. Terraform) (2) | 2024.06.07 |